")
Back to Journals » Drug Design, Development and Therapy » Volume 19
Explainable Artificial Intelligence in the Field of Drug Research
Authors Ding Q, Yao R, Bai Y, Da L, Wang Y, Xiang R, Jiang X, Zhai F
Received 27 February 2025
Accepted for publication 5 May 2025
Published 29 May 2025 Volume 2025:19 Pages 4501—4516
DOI https://doi.org/10.2147/DDDT.S525171
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Professor Tamer Ibrahim
Qingyao Ding,1 Rufan Yao,1 Yue Bai,1 Limu Da,1 Yujiang Wang,2 Rongwu Xiang,1,3,4 Xiwei Jiang,1 Fei Zhai1
1Faculty of Medical Devices, Shenyang Pharmaceutical University, Shenyang, Liaoning Province, People’s Republic of China; 2Department of Internal Medicine, Zhengding County People’s Hospital, Shijiazhuang, Hebei Province, People’s Republic of China; 3Liaoning Medical Big Data and Artificial Intelligence Engineering Technology Research Center, Shenyang, Liaoning Province, People’s Republic of China; 4Institute of Regulatory Science for Medical Products, Shenyang Pharmaceutical University, Shenyang, Liaoning Province, People’s Republic of China
Correspondence: Xiwei Jiang, Faculty of Medical Devices, Shenyang Pharmaceutical University, Shenyang, 110016, People’s Republic of China, Email [email protected] Fei Zhai, Faculty of Medical Devices, Shenyang Pharmaceutical University, Shenyang, 110016, People’s Republic of China, Email [email protected]
Abstract: In recent years, the widespread use of artificial intelligence (AI) and big data technologies in drug research has significantly accelerated the drug development process. However, their black-box nature makes it challenging to evaluate their effectiveness and safety. The interpretability of models has become a key issue in the application of AI in the drug development. In this paper, a bibliometric approach has been adopted to systematically analyze the application of Explainable Artificial Intelligence (XAI) techniques in drug research, with an in-depth discussion of the developmental trends, geographical distribution, journal preferences, major contributors, and research hotspots. In addition, the research results of XAI are summarized in the three directions of chemical, biological, and traditional Chinese medicine, and the future research directions and development trends are envisioned in order to promote the in-depth application of XAI technology in drug discovery and continuous innovation.
Keywords: explainable artificial intelligence, XAI, drug research, bibliometric analysis, interpretability, shapley additive explanations, SHAP
Introduction
Drug research plays a crucial role in safeguarding human health, not only providing an effective means of treating diseases but also significantly improving people’s quality of life. With the advancement of science and technology, new drug research and development (R&D) have been making progress in the fields of cancer, cardiovascular diseases, and infectious diseases, bringing new hope for the treatment of complex diseases.1 However, high R&D costs, long R&D cycles, and high failure rates in screening potential drugs at early stages make traditional drug research face bottlenecks, which not only slow down the process of launching new drugs but also limit the depth and breadth of the research.2
In this context, the rise of artificial intelligence (AI) and big data technologies has brought new opportunities for the development of drug research. These technologies are able to extract valuable information from massive amounts of biomedical data through a data-driven approach, greatly enhancing the efficiency of drug development.3 Using machine learning algorithms, researchers can more accurately predict the interactions between molecules and targets and optimize drug structures. In addition, big data-based analytics have led to a dramatic increase in the efficiency of drug screening and a significant reduction in costs. In recent years, some landmark achievements have emerged; for example, Insilico Medicine successfully discovered new antifibrotic drugs using deep learning, while the AI platform developed by Atomwise discovered drug candidates against the Ebola virus in new drug screening.4,5 These advances not only drive innovation in drug research but also lay the foundation for the future development of personalized medicine.
However, with the widespread use of AI technologies in pharmacy, new challenges have arisen. While traditional black-box models have excelled in several fields, their internal working mechanisms are complex and lack transparency, especially in high-risk drug development, where the lack of interpretability raises questions about their effectiveness and safety. In response to this bottleneck, Explainable Artificial Intelligence (XAI) has emerged. XAI technology provides an effective means to address model opacity and is increasingly being widely used in the field of pharmacy. It centers on revealing the decision-making rationale of models and enhancing system transparency, thereby improving user trust.
Based on the above background, this study systematically analyzes the current status and development trend of XAI research and application in the field of pharmacy based on bibliometric analysis. The development path and future potential of this field are revealed in terms of the number of publications, country/region distribution, journals, authors, and research hotspots and trends. The research results and future development directions are also summarized and analyzed in terms of chemical, biological, and traditional Chinese medicines (TCM), aiming to provide a comprehensive reference and scientific basis for subsequent research.
Bibliometric Analysis
Data Sources and Analysis Methods
The data of this study came from the database “Web of Science Core Collection”. It was found using advanced search mode with the following search formulas: #1: TS = (AI OR “Artificial Intelligence” OR “machine learning” OR “deep learning”); #2: TS = (interpretable OR explainable OR Shapley OR SHAP OR LIME OR explainability OR interpretability); #3: TS = (drug OR pharma*). The final search formula is #1 AND #2 AND #3. To obtain as many relevant sources as possible, we use wildcards (*) to denote one or more other characters and to allow for variable endings of keywords. For example, “pharma*” should include the words “pharmacy” and “pharmaceutical”. We set the time frame from 2002.01.01 to 2024.06.30, limited the language to English, and restricted the type of publication to articles and reviews, resulting in a total of 920 articles. Three staff members meticulously reevaluated the 920 articles from the initial screening to confirm their relevance to drug research and their use of interpretable models or techniques, ultimately obtaining 573 representative and scientifically valid articles. Figure 1A outlines the specific research process and screening criteria.
 |
Figure 1 Research Process and Quantity/Quality of Issues Analyzed. (A) the overall flow of bibliometric research. (B) the trend of the number of articles published in the field: the bar graph indicates the number of articles published in the year, the dashed line indicates the cumulative number of articles published up to the year, and the dotted line indicates the predicted trend of the cumulative number of articles. (C) the schematic diagram of article quality in recent years: he diagram uses TC/TP to indicate article quality; TC represents the number of citations an article has received, TP represents the number of articles published in that year, the vertical coordinate indicates the year of publication, and the vertical coordinate indicates the year of citation after publication. |
This study utilized Microsoft Excel for basic statistical analysis of publications and citations per year, countries/regions, institutions, journals, authors, and keywords. VOSviewer 1.6.20 was used for research institution collaboration analysis and combined with Scimago Graphica software for country/region collaboration analysis. Reference burst detection using CiteSpace V6.3. Author analysis and keyword analysis were performed using the bibliometrix toolkit, and publications and citations per year were visualized using the Chiplot online mapping platform (https://www.chiplot.online/) website.
Literature Volume and Distribution
Number of Publications
Figure 1B illustrates the annual publication trends in the field in recent years. In 2017 and before, the annual average number of publications (TP) remained below 5; from 2019 to 2021, TP increased significantly, reaching an annual average of 36.3; and from 2022 to 2024, the annual average TP exceeded 100, though the number decreased slightly in 2024, owing to the fact that the statistics only cover the period up to June 2024. In this study, the autoregressive integral sliding average (ARIMA) model (R2 = 0.9934) was used to conduct time series analysis and forecast the cumulative TP. Based on historical data, the ARIMA model predicts that the cumulative TP in the topic will reach 694 by 2024. Further analysis of the model’s extrapolated trend shows that the TP in this topic will continue to rise in the future, indicating that the research activity and academic attention in this area are continuously increasing. Therefore, it can be reasonably presumed that the number of articles published in this field will maintain an upward trend in the next few years under the continuous attention and research promotion of the academic community.
In this study, we evaluated the quality of the literature using the “TC/TP” metric, which measures the academic influence of papers.6 The heat map of article quality in Figure 1C further illustrates the quality of articles in each year. Before 2018, there were few published articles, the topic received little attention, and the research field was in its early stages of exploration. 2018 was a turning point for the rapid growth and high-quality development of the field, with a significant increase in the TC/TP value, which remained high at 15 to 16 in the following years. The peak in TC/TP values in 2020 is a milestone in the high-quality development of the field, reflecting the fact that papers published in 2020 are frequently cited. Between 2018 and 2021, the TC/TP values generally exceeded 10, and the number of publications also showed a rapid growth trend, and the research field was in a period of rapid growth. From 2022 to the present, the research in the field is still developing steadily, and the number of publications has increased, so that in the future, as time passes, high-quality literature and research achievements will be gradually highlighted.
Countries/Regions
Figure 2A shows the geographic map of the number of publications. The top ten countries on the map are concentrated in Asia, Europe, and North America, with China having the most articles (212), and the United States having the second-most articles (145). We collected information on the top ten countries in terms of publication count (Table 1). The top three countries in terms of TC/TP value are Switzerland (33.95), Germany (31.06), and Thailand (26.74), and each of these three countries shows obvious research features and unique advantages in the application of XAI to pharmacy. Switzerland has become an industry leader in molecular property prediction and drug safety, especially in utilizing advanced technologies to address safety issues in drug development.7–9 This country has not only made great advances in theoretical research, but it has also enhanced the safety assessment of chemical drugs in actual applications, providing valuable experience for other countries. Germany, on the other hand, has proved its vast research horizons by focusing on the application of XAI in pharmacy since 2002,10 with particularly impressive outcomes in cutting-edge technologies such as multi-target compounds and drug response prediction.11 Since 2018, Germany’s research output has increased dramatically, indicating a high potential for interdisciplinary integration capabilities in drug discovery and development, which provides more comprehensive and precise support for new drug discovery and development.7,12 Thailand, although a late starter, has entered this field since 2015, and its publication volume has expanded dramatically since 2019, reflecting its rapid development in biologics drug discovery and development. Particularly in peptides and protein applications targeting bacterial infections and cancer,13,14 Thai research has used integrated models and multiple technological tools,14–16 indicating its adaptability and usefulness in technological innovation.
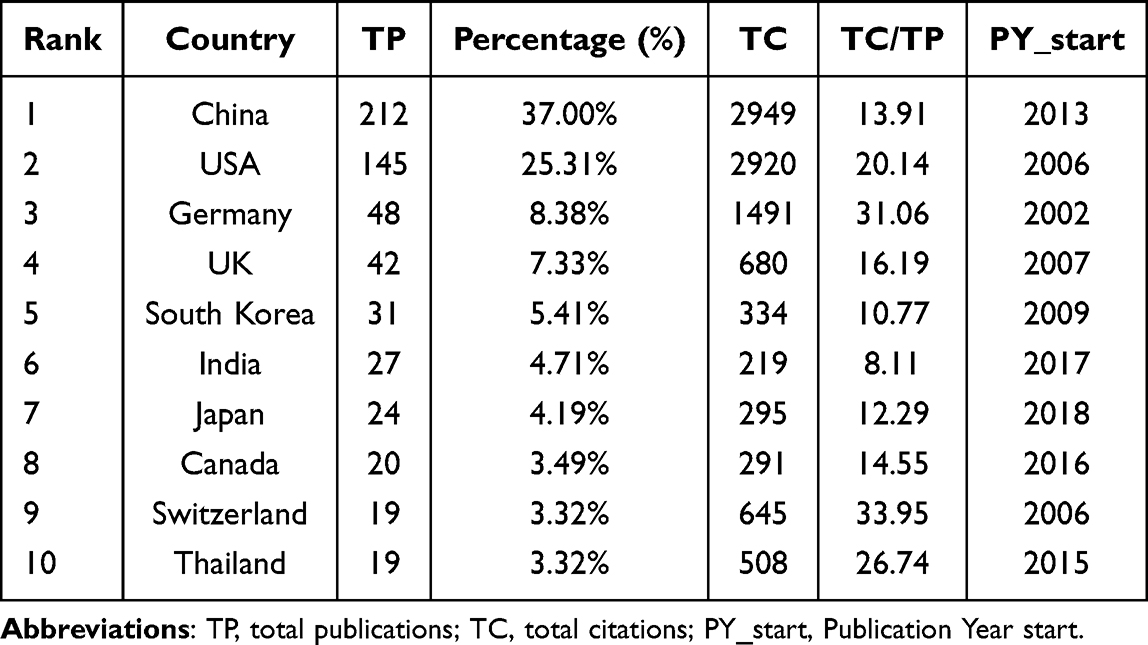 |
Table 1 Top 10 highly Producing Countries and Regions |
 |
Figure 2 Analysis of research countries, institutions, and authors (A) the geographic map of article publishing in this field. (B) the country cooperation map: the size of each country node indicates the number of articles published in that country, and the node color shade indicates the intensity of the country’s cooperation; the darker the color, the more cooperation with other countries, and the connecting line between two nodes indicates that the two countries are cooperating. (C) the time node graph of the top 10 authors’ publications: the horizontal coordinate is the year of publication, the size of each node indicates the number of publications, and the color of the node indicates the number of times the article has been cited. (D) the network diagram of institutional cooperation: nodes of the same color indicate that the research direction of these institutions is similar. |
Figure 2B shows a graph of country partnerships, and we find a positive relationship between the intensity of cooperation and the number of country publications. Among the 55 countries that have conducted research in this field, the United States ranks first in terms of cooperation intensity, having established scientific cooperation with 29 countries, followed by China, which has cooperation with 24 countries. And the partnership between China and the United States is particularly noteworthy. Other high-yielding countries, such as Germany and Switzerland, also maintain good research cooperation. In addition, the intensity of cooperation is affected by a variety of factors, including the country’s level of economic development, geographic proximity, and political relations between countries. For example, academic exchanges and cooperation between the United States and its allies, such as the United Kingdom and Germany, are also frequent. China, on the other hand, also has more cooperative interactions with neighboring countries like Japan, Pakistan, and Singapore.
Publishing Journals, Scholars, and Institutions
Publishing Journals
Table 2 shows the top ten journals in terms of TP value, with the vast majority of them placed in Q1. More than half of the journals have focused on research in this field since around 2010, which is forward-looking. JOURNAL OF CHEMICAL INFORMATION AND MODELING is ranked top in both TP and TC and is the first journal to focus on this field. BRIEFINGS IN BIOINFORMATICS has only been focusing on this area of research since 2021 but has quickly become a popular journal for publishing high-quality papers in this field. Although these journals have high TP and TC values, the IF average is only 4.91, indicating that their total academic level and impact have not yet achieved peak levels. Although their research contributions in this field should not be ignored, there is still a gap when compared to the top international journals, reflecting that some of the research in this field may be focused on application exploration rather than innovative breakthroughs of historic significance. Table 3 displays the top ten journals with TP/TC values greater than 50 and an IF mean of 12.55, covering a wide range of disciplines including pharmacy, chemistry, biology, medicine, and artificial intelligence, which shows XAI’s diversity and development potential in the field of pharmacy research. CANCER CELL was ranked first, with an impact factor (IF) of up to 48.8. In 2020, the journal published an article in which researchers developed visible neural networks (VNNs) to shed light on the synergistic mechanisms of cancer drugs by mapping neurons of deep neural networks directly to large hierarchical structures of known and putative molecular components and pathways, providing new perspectives and directions for cancer drug research.17 Furthermore, in these high-impact journals with TC values over 100, researchers have extensively used deep learning network models to probe deeply into drug-molecule interactions, and they have primarily used attention mechanisms and deep learning mapping techniques to improve the interpretability of their studies.12,18 The majority of these highly cited literature published in high-quality academic journals occurred around 2020, when the TP/TC metrics peaked with more than 100 citations in all five journals.
 |
Table 2 Top 10 Journals in Terms of Publications |
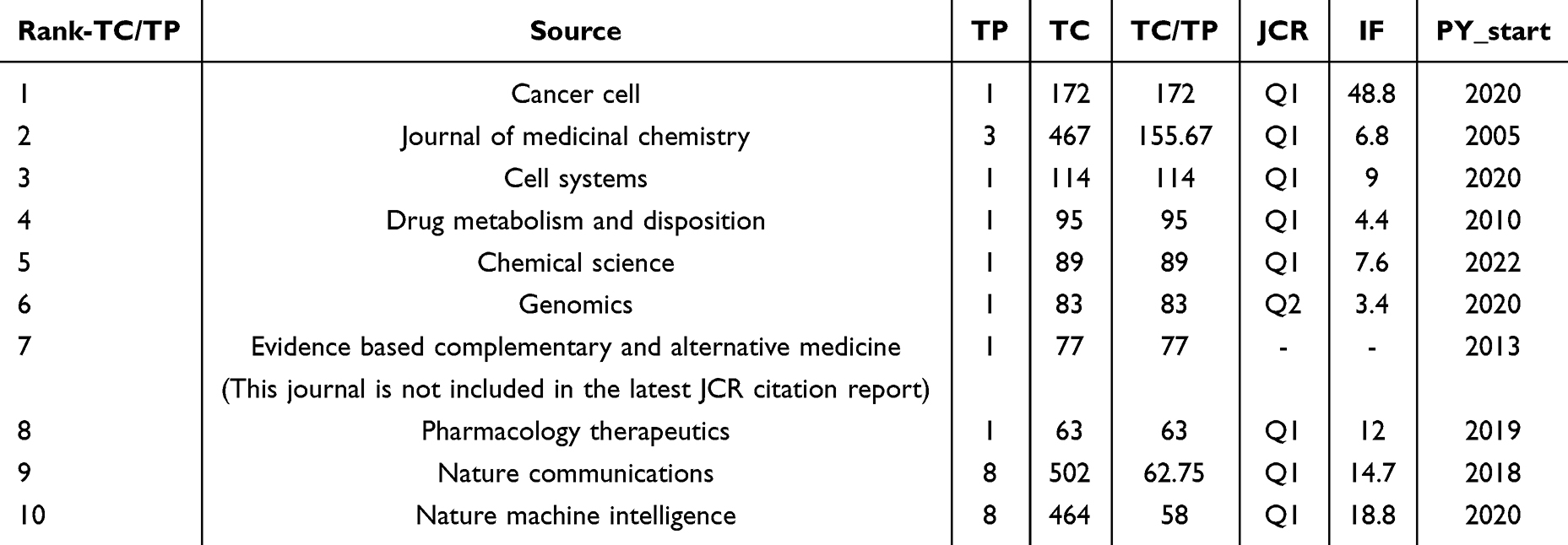 |
Table 3 Top 10 Journals in Terms of Average Citations |
Scholars
Figure 2C depicts a time series plot of authors’ publication volume, revealing that the peak of publication in the research concentration occurs after 2019, and the articles with high citation counts are all distributed between 2019 and 2021, coinciding with the rapid growth period of publication volume. Four of the top ten authors are from Thailand, one from Germany, and the rest are from China. Among these authors, Shoombuatong, Watshara has the highest publishing volume, with 15 academic papers. His 2019 publication, “ACPred: A Computational Tool for the Prediction and Analysis of Anticancer Peptides”, has received 128 citations. The study constructed an interpretable predictive model by integrating multiple peptide features and combining Random Forest and Support Vector Machine algorithms. By analyzing key features, the model reveals the biophysical and biochemical mechanisms behind the anticancer activity of peptides, and the if-then rule taken from the random forest model adds transparency to the model’s prediction logic.16 Furthermore, Shoombuatong, Watshara (15 papers) works closely with Schaduangrat, Nalini (12 articles), Nantasenamat, Chanin (9 articles), and Charoenkwan, Phasit (9 articles), all of whom conduct research on functional peptide analysis and prediction. The first three authors, all from Mahidol University, have focused their research on random forests or SHAP as interpretable techniques to reveal key features of different functional peptides.15,19 Charoenkwan Phasit, on the other hand, is from Chiang Mai University, and his studies mostly used the Score Card Method (SCM) and its variations to identify and characterize functional peptides.13,20 Since 2020, German author Juergen Bajorath has published 11 papers in this field. His first paper published in 2020, “Interpretation of Machine Learning Models Using Shapley Values: Application to Compound Potency and Multi-Target Activity Predictions” has been cited 236 times. The study used SHAP methodology to identify and rank the key features that determine compound classification and activity prediction. It also demonstrated how SHAP analysis can be used to decipher the multi-target activity profiles generated by DNN models, revealing molecular structural features that have a significant impact on biological activity.11 In addition, in 2021, Hou Tingjun published the paper “Could Graph Neural Networks Learn Better Molecular Representation for Drug Discovery? A Comparison Study of Descriptor-Based and Graph-Based Models”, which has been cited 246 times, explored the application of graph neural networks (GNN) in molecular property prediction and significantly revealed the key molecular descriptors and structural features learned by the prediction models with the help of the SHAP method, providing a profound insight into the accurate prediction of molecular properties.21
Institutions
Figure 2D shows the network diagram of institutional collaboration. The large collaborative networks in the network diagram are mainly composed of Chinese universities and research institutes, with fewer international large collaborative networks. For example, in the blue clusters, institutions such as Zhejiang University and Central South University, Hong Kong Baptist University, Lanzhou University, and Tsinghua University show a wide range of collaborative networks, and their research interests cover a wide range of fields. Furthermore, the purple cluster depicts the collaborative network between Chinese research institutions and the University of Tsukuba in Japan, whereas the green cluster represents the collaborative relationship between Chinese research institutions and the global biopharmaceutical company AstraZeneca. The yellow cluster, which includes Mahidol University, Chiang Mai University, the University of Cambridge, and the University of Queensland, is particularly noteworthy. These collaborations have focused on biologics research, particularly the screening, identification, and analysis of functional proteins, with many of these studies using gene sequence and protein sequence correlation information. In addition, some institutions, such as the University of Bonn, are actively focusing on intra-institutional exchanges. The current analysis of collaboration networks reveals a clear trend: most research institutions’ collaborations are mainly focused on the domestic level, while collaboration networks on a global scale are not yet widely connected. This occurrence shows that, despite frequent localized collaborations, there is still much room for worldwide research cooperation to grow. To promote the continuous development and innovation in this field, future research efforts need to pay more attention to and actively build cross-border and interdisciplinary cooperation networks.
Research Hotspots and Trends
Analysis of Reference Bursts
Figure 3A is a reference emergence map showing the top 50 high-frequency cited references. The research content of the highly cited references focuses on three core directions (Supplementary Table 1): drug research (29), technology research (17), and database introduction (4). Examples include the prediction of target activities and properties of compounds by Mordred molecular descriptor computational software and the use of XAI techniques for prediction of molecular properties and new drug design.9,22 Also included are the presentation of XAI techniques such as SHAP, LIME, and Transformer23–25 and databases such as PubChem and ChEMBL.26,27 The analysis in Figure 3A also shows that the duration of the emergence of the most highly cited articles is relatively short, mostly between 1 and 2 years, which reflects the rapid updating of knowledge and the rapid development of the field. And the bursting period of most references is concentrated in 2019 to 2024, which is consistent with the field’s rapid growth. Although these highly cited papers have not yet applied interpretable techniques directly to the field of drug research, they provide an important theoretical foundation and reference value for the application of XAI techniques in drug research.
 |
Figure 3 Research hotspot analysis (A) the reference highlighting graph: dark blue on the right side of the graph indicates the cited time period of the literature, and red indicates the highlighting time period; (B) the keyword network graph; (C) the graph of the frequency of the TOP15 keyword appearance time; (D) the strategic graph of the research trend. |
Keywords Analysis
Figure 3B shows the keyword clustering results based on Louvain’s community discovery algorithm, revealing four main clusters. The red clustering focuses on machine learning models (eg, Random Forest and XGBoost) and natural language processing as core research tools, focusing on drug design, screening, and safety assessment.28,29 In this clustering, XAI techniques, especially SHAP and knowledge graphs, are prominently used to enhance the explanatory power of models.30,31 Blue clustering, on the other hand, uses deep learning models like graph neural networks and transformer to explore drug-drug interactions, as well as drug-target binding affinity. In this clustering, the attention mechanism is widely used for model interpretation, aiming to identify and emphasize the key elements in the input features.32,33 The green clustering focuses on drug development and drug repositioning for specific diseases such as cancer and COVID-19.34 The purple clustering, on the other hand, focuses on drug response prediction and precision medicine using convolutional networks.35,36 Overall, XAI technology plays an important role in several areas of drug research, covering a wide range of applications from drug design to precision medicine.
In addition, Figure 3C shows the temporal distribution of the top 15 high-frequency keywords. The analysis results show that before 2018, the frequency of keywords was low, mainly focusing on methods such as machine learning, QSAR, feature selection, etc., and the application field only focused on drug discovery. This indicates that in the early exploration stage, the research method and application direction of this field are single, and a comprehensive research system has not yet been formed. In 2019, the deep learning and interpretability keywords began to appear, especially the frequency of deep learning increased year by year, and it became a technical hotspot in the field. In 2020, the concept of XAI began to be paid attention to, and the heat continued to increase. At the same time, SHAP and attention mechanisms began to be noticed by researchers as emerging XAI technologies. “Drug-Target Interaction”, as an emerging application direction, quickly ranked 10th in the cumulative frequency ranking, signaling that it has become an emerging research hotspot in the field. 2021 SHAP technology began to enter the researchers’ field of vision, and due to its ability to adapt to a variety of models, it has become a popular choice for XAI techniques in the field. At the same time, the application field is gradually expanding to COVID-19, bioinformatics, and more widely used in various fields of drug research.
Based on the keyword strategy map presented in Figure 3D and Supplementary Table 2, it is evident that machine learning, deep learning, and interpretability are the core pillars of development in the field. Research on these themes covers the entire process of drug development, including drug discovery and design, drug response prediction, and drug regulation. As fundamental themes, they provide a wealth of technical tools that lay a solid theoretical foundation and technical support for the entire research field. XAI and bioinformatics are key drivers of progress in this field, and their application in drug discovery and development has achieved remarkable results. XAI can improve the transparency and interpretability of models, helping researchers identify and explain the mechanism of action of drugs, predict their side effects, and optimize their drug design solutions. Bioinformatics provides rich basic data for drug discovery through data mining, genomics, and proteomics. Combined with XAI, bioinformatics not only deepens the understanding of biological systems but also facilitates personalized medicine and precision drug development. The two have shown a favorable development trend and high relevance in the field. Although niche topics such as cancer, chemoinformatics, and adverse drug reaction prediction studies are not as influential as core topics such as XAI in the field, the research in these categories is also sufficiently in-depth and specialized to be well developed. It is worth noting that drug interactions and SHAP, as emerging research themes, are seeing a rise in their interest in the field, which bodes well for future research that may focus more on this theme.
With the continuous innovation of AI algorithms and interpretable techniques and tools, XAI is being widely used in various fields of drug research. In particular, the wide application of techniques such as SHAP enables researchers to quantify the importance of model features, which strengthens the transparency and interpretability of models. Meanwhile, techniques such as graph neural networks and attention mechanisms not only enhance the interpretability of deep learning models but also show strong application potential in drug-drug interaction and drug-target interaction studies. In recent years, the research theme has also expanded from single drug discovery to precision medicine, drug repositioning, and other fields, indicating that the research methodology and application direction in this field are gradually maturing.
Discussion
Application of XAI in Chemical Drugs
XAI technology is widely used in chemical drug research, covering many aspects of drug development, including prediction of molecular properties, drug interaction studies, drug safety and regulation, and many other aspects.
In terms of molecular property prediction, XAI has been widely used for biological activity, physicochemical properties, and toxicity studies. For biological activity, the Permutation Feature Importance technique and SHAP analysis reveal the key pharmacophoric features of compounds and the relationship between descriptors and the effect on activity, such as assessing binding affinity towards key active site amino acid residues and clarifying what features determine selective affinity for serotonin receptors.37,38 In addition, local interpretable model-agnostic explanations and counterfactual analysis, which can identify key compound features influencing the property, help optimize compound structures and enhance drug design efficiency.39 In terms of physicochemical properties, SHAP and graph neural networks combined with concept whitening (CW) are used to identify key molecular features of properties such as solubility, lipophilicity, and partition coefficient, and to clarify the drivers of chemical modifications.21,40,41 In toxicity studies, SHAP, layer-wise relevance propagation (LRP), and feature importance analysis revealed key features associated with cytotoxicity, fetotoxicity, and cardiotoxicity, such as amine groups and aromatic groups, which provided intuitive support and a reliable basis for toxicity prediction models.42–44
In drug-drug interaction research, XAI provides biologically meaningful explanations for model predictions through attention mechanisms, feature importance, analysis and other methods, significantly improving the interpretability of models. In drug-target interaction (DTI) studies, the attention mechanism and visualization tools help to reveal the interaction mechanism between drug molecules and target proteins, which not only locates the binding site but also identifies the roles of key residues in the binding process.32 Inspired by the gradient-weighted class activation mapping method, the regions of graph structure that contribute most to the affinity prediction results are visualized as heatmaps, and the overlap of the results with molecular docking sites was more than 77%, indicating that this method can effectively characterize the active structure of drug molecules and provide directions for molecular optimization.45 In addition, by visualizing the atomic importance of molecules through Grad-CAM, researchers have further clarified the contribution of amino acids and atoms in drug-target binding, providing a specific reference for protein target-based drug design.46 In drug-drug interaction (DDI) studies, co-attention matrices and self-attentive mechanisms have been used to analyze the contribution of different substructures of a drug molecule to interaction prediction, generating subgraph summaries of inference pathways that reveal the underlying mechanisms of drug-drug interactions.47,48 The combination of t-SNE and molecular representation visualization techniques further identified key local structures, providing an important reference for molecular design and optimization.49
XAI technology also plays an important role in drug safety and regulation. SHAP values aid drug safety assessment by quantifying the contribution of features to model predictions, such as the ability to identify key factors when assessing the risk of acute orthostatic hypotension (OH) post-levodopa (AOHPL) administration in Parkinson’s disease patients, as well as interpreting the predictions of different classifier models in drug-induced cardiotoxicity studies.50,51 Generative topographic mapping (GTM), a non-linear dimensionality reduction method, has been used for antibiotic-wise comparison and visualization of resistant phenotypes, revealing the mechanisms of antibiotic resistance development.52 In drug-induced liver injury (DILI) assessment, ranked feature importance is used in conjunction with attention weights to identify key features affecting DILI prediction on the one hand and to highlight specific molecular substructures that were highly related to the DILI prediction for each compound on the other hand to guide drug design.53 In addition, the combination of attention mechanisms and integral gradients has improved the understanding of predictive modeling of drug side effects, revealing underlying biological mechanisms, such as the identification of key proteins and phenotypes in studies of acute liver failure.30,54
In the field of clinical decision support, a random forest model was used to predict the efficacy of nonsteroidal anti-inflammatory drugs (NSAIDs) for closing hemodynamically significant patent ductus arteriosus (hsPDA) in preterm infants. Five key variables were identified through the model’s built-in characteristic importance analysis, and marginal-effect plots based on the top three most important variables clearly demonstrate the nonlinear relationship between the independent and dependent variables.55 In teratogenicity and cytotoxicity assessment, the characteristic importance analysis of the random forest model was used to compare the importance of the embryonic stem cell and discover the characteristics of the association between teratogenicity and cytotoxicity of the compounds, and a generalized linear regression model combined with a Bayesian network was also constructed to reveal the potential effects among the embryonic stem cell.55 In addition, researchers have interpreted estimation of the synthetic accessibility of small molecules with the help of attention mechanism visualization, which helps to understand model learning and the effect of structural differences on synthetic accessibility by visualizing atomic weights.56
Application of XAI in Biological Drugs
Biological drugs occupy an increasingly important position in modern medicine, and the research of biological drugs combined with XAI is mainly focused on peptide drugs.
In the study of antimicrobial peptide (AMP), XAI technology has revealed the importance of different features for ABP identification and prediction through methods such as SHAP and Gini importance analysis.57,58 These analyses improve the transparency and interpretability of the model while optimizing the AMP design. For example, it has been shown that overall energy estimation-based (RCEMT_75, RCEMT_46, RCEMT_172, and RCEMT_40), physicochemical (ExPseAAC_26, ExPseAAC_22, and ExPseAAC_21), and sequential-based properties (DDE_262, DDE_218, and DDE_149) contributed well to predicting accurate anti-Methicillin-resistant Staphylococcus aureus (MRSA) peptides.14
In the field of anticancer peptides (ACPs), t-SNE visualization and SHAP analysis were used to demonstrate the ability of each module of the model to extract features and reveal the critical impact of the physicochemical properties and the compositional properties on the model prediction results.59–61 Gini importance analysis further revealed the distribution of different features’ contribution in ACP prediction, which can help in designing more effective and selective ACPs.62,63
In neuropeptides (NPs) research, SHAP is used to evaluate the saliency of each feature, which solves the lack of feature directivity problem and makes the feature selection more scientific and reasonable. By calculating the shap value and selecting the top-ranked features, the feature vector was optimized and the performance of the model was improved. These findings provide specific biological and chemical insights for optimizing NPs classification and help to design more effective and selective NPs recognition models.15,64
In antiviral peptide (AVP) studies, variable importance plots and SHAP plots were used to assess the importance of features and to understand the average impact of features on model predictions.65 The 35 highest-ranked features were selected by SHAP analysis through interpreting the importance of each feature to the model prediction, which significantly improved the prediction rate of the model.66
Other types of peptide drug studies have also utilized XAI technology. For example, SCM effectively captured key information about quorum sensing peptides (QSPs) and improved prediction performance. t-SNE visualization demonstrated the advantages of feature vectors of the optimal propensity scores in distinguishing QSP classes, while the identification of important physicochemical properties revealed the biological mechanisms behind the model predictions.67 In addition, the use of SCM provided insight into the biophysical and biochemical properties of blood-brain barrier penetrating peptides (B3PPs), which helped to understand their functional mechanisms and guide future experimental validation.68 Models constructed based on the SCM were used to analyze and understand the biophysical and biochemical properties of bitter peptides, thus providing insight into the properties of bitter peptides.69
In addition, decision tree classifier as model architecture was used for antibody viscosity classification, optimizing the development and production process for rational redesign of antibodies through its simplicity and interpretability.70 Gaussian naïve Bayes classifiers, on the other hand, have a high level of classification accuracy for self-association and accuracy for non-specific binding by limiting the number of features and selecting the most relevant ones, again providing valuable biological and chemical information for rational antibody redesign.71 Moreover, the LRP (Layer-wise Relevance Propagation) technique has been applied to analyze insulin infusion rates, which provides a deeper understanding of diabetes treatment by determining the contribution of each variable to the decision on insulin infusion rates by assigning the output values to the input states in an inverse manner.72
Application of XAI in Traditional Chinese Medicine (TCM)
The multi-component, multi-target, and multi-pathway characteristics of TCM lead to the diversity and complexity of TCM data, which hinders the process of modernization research of TCM. The application of artificial intelligence technology to the research of the dispensing mechanism of Chinese herbal medicine, the similarity of drugs, and data mining of Chinese herbal formulas can effectively promote the modernization and scientific process of TCM research.73–75 However, the prediction results of AI applied to TCM research lacked interpretability and were difficult to understand and convince, and the application of XAI solved this problem. XAI has achieved some results in the quality testing of TCM, the prediction of effective active ingredients of TCM, and the research of personalized drug delivery,75–77 which not only accelerated the process of modernization of TCM but also strengthened the combination of TCM and the modern pharmaceutical system.
In the study of the mechanism of action of TCM, network pharmacology based on complex network technology can visualize the relationship among drugs, targets, and pathways by constructing networks, which can reveal the mechanism of action of TCM at the molecular level.78 In the study of TCM efficacy, the decision tree model itself has strong interpretability, and the traditional C4.5 decision tree algorithm can be improved based on the introduction of Conditional Mutual Information (CMI) to predict and analyze the effects of exterior releasing, tonifying and replenishing, heat-clearing, wind dampness dispelling, and other herbal effects.79
In addition, Ma, Jing et al combined the SHAP technique to screen important variables related to the dosage of Shengmai injection by calculating the SHAP values to achieve an interpretable study of personalized administration of Chinese herbal medicine. Finally, in terms of quality control of herbal medicines, the authors and others combined the t-distributed stochastic neighborhood embedding (t-SNE) technique and multivariate modeling to achieve the identification and interpretable visualization of herbal medicines.80
Among the 573 retrieved documents, there are less than 10 studies related to TCM, which indicates that the application of XAI in the field of TCM research is in its infancy, and both the techniques used and the fields of application are limited.
Interpretability techniques do have a broad application prospect in the field of TCM research. In particular, interpretable techniques have the potential to assist in the analysis of the mechanism of action of TCM formulas, the in-depth exploration of the rules of drug compounding, and the research on the safety and efficacy of TCM. The choice of interpretable techniques is extremely wide; in addition to the widely used methods such as network pharmacology and SHAP value analysis, we can also consider the integration of local interpretable model-agnostic interpretation (LIME), partial dependence plots (PDP) and other techniques. Considering the multidimensionality, complexity, and nonlinear characteristics of TCM research data, appropriate methods should be used accordingly for different studies; eg, causal inference can be used when studying the effects of TCM ingredients on specific biological targets, ie, exploring a clear causal relationship, while the LIME technique can provide intuitive local interpretations when performing pattern recognition of large-scale datasets. In addition, for multi-omics data analysis of TCM ingredients, the use of deep learning models combined with interpretable deep learning techniques can reveal key information hidden in complex data structures. By combining advanced XAI technology, it can not only improve researchers’ understanding of the complex mechanism of action of TCM but also provide more scientific treatment plans for the clinical use of TCM and promote the development of TCM in the direction of being more scientific and precise.
Prospects and Challenges
In summary, XAI technology has been widely used in several aspects of drug research. These applications demonstrate the potential of XAI to enhance the efficiency of the drug development process, reduce costs, and accelerate innovation. In addition, XAI provides researchers and clinicians with a deeper understanding by enhancing the transparency and credibility of the models, thus enabling them to have more trust in and effectively utilize the predicted results of AI systems. However, despite significant progress in the application of XAI in drug research, several challenges remain.
The first is the balance between model accuracy and interpretability. While pursuing the interpretability of a model, it is a key challenge to maintain or enhance the predictive accuracy of the model. For example, in drug response prediction, decision tree models are easy to interpret due to the transparency of their structure, allowing researchers to clearly trace the decision path of the model. However, the simplifying assumptions of decision trees may limit their ability to capture complex patterns in the data, which in turn affects the predictive accuracy of the model. Comparatively, while gradient boosting models such as XGBoost perform better in terms of prediction accuracy, their inherent complexity and lack of intuitive interpretation may lead to questionable model credibility. To achieve a balance between model accuracy and interpretability, researchers have explored strategies to develop variants of existing models or model fusion. These approaches can reveal the decision-making process of the model to a certain extent, thus increasing the transparency of the model. However, these efforts do not always fully satisfy the need for a global interpretation of the model.
The second is the quality of the data and the complexity of modeling biological systems. The validity of XAI relies heavily on the quality and completeness of the input data. In pharmaceutical research, missing, biased, or noisy data may affect the explanatory power of the model and the reliability of the predicted results. In addition, the high complexity and dynamics of biological systems pose challenges to the construction and interpretation of XAI models. For example, in drug interaction analysis, the interactions of multiple biomolecules and pathways need to be considered, which increases the complexity of the model.
The third is that a unified and reasonable standard has not yet been formed to assess whether model interpretation is accurate and reasonable. Traditional assessment metrics usually focus on evaluating the predictive performance of a model, while the assessment of the interpretability itself currently relies on subjective judgment and lacks a unified framework and standard. For example, the SHAP value can assign an importance score to each feature but does not provide clear criteria to judge whether this score is consistent with the actual causal relationship or data distribution. The expert’s empirical judgment is usually the only assessment criterion, which not only brings about subjectivity in assessment but also leads to poor comparability of results between different methods.
Therefore, future research should be devoted to the simultaneous improvement of model interpretability and accuracy, the development of XAI technology that is less dependent on data quality and has the ability to simulate the behavioral patterns of complex biological systems, and the development of a unified and scientific interpretability assessment framework in conjunction with the characteristics of pharmaceutical research. This will help promote the in-depth development of XAI technology in the field of pharmaceutical research, address the key technical challenges currently faced, and push the field to new heights.
Conclusion
In this paper, 573 publications from 55 countries/regions were comprehensively analyzed by bibliometric methods to reveal the research progress and trends of interpretable artificial intelligence (XAI) technology in drug discovery and development. The analysis of the number of publications shows that the attention and application of XAI technology in the field of drug research continues to grow, reflecting the gradual importance and strong development potential of this technology in drug discovery and development.
In terms of country/region distribution, China and the United States not only lead in the number of publications but also play an important role in international cooperation. Although a certain scale of cooperation network has been formed in this field, collaborative research on a global scale is still insufficient. With their high-quality research results, Switzerland, Germany, and Thailand have made significant progress in exploring innovative applications of XAI.
The keyword analysis shows that XAI is deeply integrated with artificial intelligence, machine learning, deep learning, and other technologies, and SHAP and attention mechanisms are the commonly used interpretable techniques in the field of drug research at present. The application of these techniques not only enhances the interpretability of drug development models but also provides more transparent and reliable theoretical support for drug design, optimization, and validation.
This paper also discusses the current status of the XAI application in the fields of chemical, biological, and TCM, providing a clear prospective perspective for future research directions. It also looks forward to the future innovation and development direction of this technology in the field of drug research from three perspectives: model performance, data quality, and evaluation criteria. With the continuous development of XAI technology, it will play a more important role in various fields of drug research in the future, helping the realization of personalized medicine, precision therapy, and modernization research of TCM. In this regard, international cooperation should be further strengthened to promote cross-field integration of technology applications and improve the existing technological framework so as to promote the innovation and development of global drug research and development.
Abbreviations
XAI, Explainable Artificial Intelligence; AI, Artificial Intelligence; R&D, Research and Development; ARIMA, autoregressive integral sliding average; TC, Total Citations; TP, Total Publications; IF, Impact Factor; VNNs, Visible Neural Networks; SVM, Support Vector Machine; SCM, Score Card Method; SHAP, Shapley additive explanations; LIME, Local Interpretable Model-agnostic Explanations; GNN, graph neural networks; DTI, drug - target interaction; DDI, drug - drug interaction; t - SNE, t - Distributed Stochastic Neighbor Embedding; GTM, Generative Topographic Mapping; DILI, drug - induced liver injury; NSAIDs, nonsteroidal anti - inflammatory drugs; hsPDA, hemodynamically significant patent ductus arteriosus; AMP, antimicrobial peptide; ACP, anticancer peptide; NP, neuropeptide; AVP, antiviral peptide; QSPs, quorum sensing peptides; B3PPs, blood - brain barrier penetrating peptides; LRP, Layer - wise Relevance Propagation; TCM, Traditional Chinese Medicine; CMI, Conditional Mutual Information.
Data Sharing Statement
This is a review article based on data acquired from the Web of Science database.
Author Contributions
All authors made a significant contribution to the work reported, whether that is in the conception, study design, execution, acquisition of data, analysis and interpretation, or in all these areas took part in drafting, revising or critically reviewing the article; gave final approval of the version to be published; have agreed on the journal to which the article has been submitted; and agree to be accountable for all aspects of the work.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. The General Project supported by Basic Scientific Research Project of Liaoning Provincial Department of Education (LJKFZ20220258), the Scientific Research Foundation of the Education Bureau of Liaoning Province (LJKR0302). The funders had no involvement in paper design, data collection, data analysis, interpretation, writing of the paper.
Disclosure
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
1. Lu M, Yin J, Zhu Q, et al. Artificial intelligence in pharmaceutical sciences. Engineering. 2023;27:37–69.
2. Kim H, Kim E, Lee I, Bae B, Park M, Nam H. Artificial intelligence in drug discovery: a comprehensive review of data-driven and machine learning approaches. Biotechnol Bioprocess Engineering. 2020;25(6):895–930. doi:10.1007/s12257-020-0049-y
3. Ling X, Zhao Z, Li X. Application of artificial intelligence technology in pharmaceutical field: visualization analysis of literature based on web of science. China Pharm. 2019;30(04):433–438.
4. Abbas MKG, Rassam A, Karamshahi F, Abunora R, Abouseada M. The role of AI in drug discovery. Chembiochem. 2024;25(14):e202300816. doi:10.1002/cbic.202300816
5. Zhuang D, Ibrahim AK. Deep learning for drug discovery: a study of identifying high efficacy drug compounds using a cascade transfer learning approach. Appl Sci. 2021;11(17):7772. doi:10.3390/app11177772
6. Chen Y, Song C, Zhou J, Zuo J, Wang L. Study on the factors affecting the citation frequency of papers from the perspective of bibliometrics——comment on the relationship between usage and citation. J Intelligence. 2019;38(4):96–104.
7. Manica M, Oskooei A, Born J, Subramanian V, Sáez-Rodríguez J, Rodríguez Martínez M. Toward explainable anticancer compound sensitivity prediction via multimodal attention-based convolutional encoders. Mol Pharmaceut. 2019;16(12):4797–4806. doi:10.1021/acs.molpharmaceut.9b00520
8. Rodríguez-Pérez R, Bajorath J. Explainable machine learning for property predictions in compound optimization. J Med Chem. 2021;64(24):17744–17752. doi:10.1021/acs.jmedchem.1c01789
9. Jiménez-Luna J, Skalic M, Weskamp N, Schneider G. Coloring molecules with explainable artificial intelligence for preclinical relevance assessment. J Chem Inf Model. 2021;61(3):1083–1094. doi:10.1021/acs.jcim.0c01344
10. Beerenwinkel N, Schmidt B, Walter H, et al. Diversity and complexity of HIV-1 drug resistance: a bioinformatics approach to predicting phenotype from genotype. Proc Natl Acad Sci USA. 2002;99(12):8271–8276. doi:10.1073/pnas.112177799
11. Rodríguez-Pérez R, Bajorath J. Interpretation of machine learning models using shapley values: application to compound potency and multi-target activity predictions. J Computer-Aided Mol Design. 2020;34(10):1013–1026. doi:10.1007/s10822-020-00314-0
12. Mardt A, Pasquali L, Wu H, Noé F. VAMPnets for deep learning of molecular kinetics. Nat Commun. 2018;9(1):5. doi:10.1038/s41467-017-02388-1
13. Charoenkwan P, Kanthawong S, Schaduangrat N, Yana J, Shoombuatong W. PVPred-SCM: improved prediction and analysis of phage virion proteins using a scoring card method. Cells. 2020;9(2):353. doi:10.3390/cells9020353
14. Arif M, Fang G, Fida H, Musleh S, Yu DJ, Alam T. iMRSAPred: improved prediction of anti-MRSA peptides using physicochemical and pairwise contact-energy properties of amino acids. ACS omega. 2024;9(2):2874–2883. doi:10.1021/acsomega.3c08303
15. Hasan MM, Alam MA, Shoombuatong W, Deng HW, Manavalan B, Kurata H. NeuroPred-FRL: an interpretable prediction model for identifying neuropeptide using feature representation learning. Briefings Bioinf. 2021;22(6). doi:10.1093/bib/bbab167
16. Schaduangrat N, Nantasenamat C, Prachayasittikul V, Shoombuatong W. ACPred: a computational tool for the prediction and analysis of anticancer peptides. Molecules. 2019;24(10):1973. doi:10.3390/molecules24101973
17. Kuenzi BM, Park J, Fong SH, et al. Predicting drug response and synergy using a deep learning model of human cancer cells. Cancer Cell. 2020;38(5):672–684.e676. doi:10.1016/j.ccell.2020.09.014
18. Xiong Z, Wang D, Liu X, et al. Pushing the boundaries of molecular representation for drug discovery with the graph attention mechanism. J Med Chem. 2020;63(16):8749–8760. doi:10.1021/acs.jmedchem.9b00959
19. Shoombuatong W, Schaduangrat N, Pratiwi R, Nantasenamat C. THPep: a machine learning-based approach for predicting tumor homing peptides. Comput Biol Chem. 2019;80:441–451. doi:10.1016/j.compbiolchem.2019.05.008
20. Charoenkwan P, Schaduangrat N, Nantasenamat C, Piacham T, Shoombuatong W. iQSP: a sequence-based tool for the prediction and analysis of quorum sensing peptides via Chou’s 5-steps rule and informative physicochemical properties. Int J Mol Sci. 2019;21(1):75. doi:10.3390/ijms21010075
21. Jiang D, Wu Z, Hsieh CY, et al. Could graph neural networks learn better molecular representation for drug discovery? A comparison study of descriptor-based and graph-based models. J Cheminf. 2021;13(1):12. doi:10.1186/s13321-020-00479-8
22. Moriwaki H, Tian YS, Kawashita N, Takagi T. Mordred: a molecular descriptor calculator. J Cheminf. 2018;10(1):4. doi:10.1186/s13321-018-0258-y
23. Lundberg SM, Lee S-I. A unified approach to interpreting model predictions.
24. Ribeiro MT, Singh S, Guestrin C. Why should I trust you?: explaining the predictions of any classifier.
25. Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need.
26. Kim S, Chen J, Cheng T, et al. PubChem in 2021: new data content and improved web interfaces. Nucleic Acids Res. 2021;49(D1):D1388–d1395. doi:10.1093/nar/gkaa971
27. Gaulton A, Hersey A, Nowotka M, et al. The ChEMBL database in 2017. Nucleic Acids Res. 2017;45(D1):D945–d954. doi:10.1093/nar/gkw1074
28. Falcón-Cano G, Molina C, Cabrera-Pérez M. Reliable prediction of caco-2 permeability by supervised recursive machine learning approaches. Pharmaceutics. 2022;14(10):1998. doi:10.3390/pharmaceutics14101998
29. Lamens A, Bajorath J. Explaining multiclass compound activity predictions using counterfactuals and shapley values. Molecules. 2023;28(14):5601. doi:10.3390/molecules28145601
30. Liang X, Li J, Fu Y, Qu L, Tan Y, Zhang P. A novel machine learning model based on sparse structure learning with adaptive graph regularization for predicting drug side effects. J Biomed Informat. 2022;132:104131. doi:10.1016/j.jbi.2022.104131
31. Hasselgren C, Oprea TI. Artificial intelligence for drug discovery: are we there yet? Annu Rev Pharmacol Toxicol. 2024;64(1):527–550. doi:10.1146/annurev-pharmtox-040323-040828
32. Monteiro NRC, Oliveira JL, Arrais JP. TAG-DTA: binding-region-guided strategy to predict drug-target affinity using transformers. Expert Syst Appl. 2024;238:122334. doi:10.1016/j.eswa.2023.122334
33. Kalakoti Y, Yadav S, Sundar D. Deep neural network-assisted drug recommendation systems for identifying potential drug-target interactions. ACS omega. 2022;7(14):12138–12146. doi:10.1021/acsomega.2c00424
34. Zeng X, Zhong K-Y, Jiang B, Li Y. Fusing sequence and structural knowledge by heterogeneous models to accurately and interpretively predict drug–target affinity. Molecules. 2023;28(24):8005. doi:10.3390/molecules28248005
35. Liu H, Yu J, Chen X, Zhang L. NeuMF: predicting anti-cancer drug response through a neural matrix factorization model. Curr Bioinform. 2022;17(9):835–847. doi:10.2174/1574893617666220609114052
36. Gimeno M, Sada Del Real K, Rubio A. Precision oncology: a review to assess interpretability in several explainable methods. Briefings Bioinf. 2023;24(4):15. doi:10.1093/bib/bbad200
37. Bhattacharjee A, Kar S, Ojha PK. Unveiling G-protein coupled receptor kinase-5 inhibitors for chronic degenerative diseases: multilayered prioritization employing explainable machine learning-driven multi-class QSAR, ligand-based pharmacophore and free energy-inspired molecular simulation. Int J Biol Macromol. 2024;269(Pt 1):131784. doi:10.1016/j.ijbiomac.2024.131784
38. Łapińska N, Pacławski A, Szlęk J, Mendyk A. Integrated QSAR models for prediction of serotonergic activity: machine learning unveiling activity and selectivity patterns of molecular descriptors. Pharmaceutics. 2024;16(3):349. doi:10.3390/pharmaceutics16030349
39. Jamrozik E, Śmieja M, Podlewska S. ADMET-PrInt: evaluation of ADMET properties: prediction and interpretation. J Chem Inf Model. 2024;64(5):1425–1432. doi:10.1021/acs.jcim.3c02038
40. Mohan B, Chang J. Chemical SuperLearner (ChemSL) - An automated machine learning framework for building physical and chemical properties model. Chem Eng Sci. 2024;294:120111. doi:10.1016/j.ces.2024.120111
41. Proietti M, Ragno A, Rosa BL, Ragno R, Capobianco R. Explainable AI in drug discovery: self-interpretable graph neural network for molecular property prediction using concept whitening. Mach Learn. 2024;113(4):2013–2044. doi:10.1007/s10994-023-06369-y
42. Jeong M, Yoo S. FetoML: interpretable predictions of the fetotoxicity of drugs based on machine learning approaches. Mol Informatics. 2024;43(6):e202300312. doi:10.1002/minf.202300312
43. Webel HE, Kimber TB, Radetzki S, Neuenschwander M, Nazaré M, Volkamer A. Revealing cytotoxic substructures in molecules using deep learning. J Computer-Aided Mol Design. 2020;34(7):731–746. doi:10.1007/s10822-020-00310-4
44. Iftkhar S, de Sá AGC, Velloso JPL, Aljarf R, Pires DEV, Ascher DB. cardioToxCSM: a web server for predicting cardiotoxicity of small molecules. J Chem Inf Model. 2022;62(20):4827–4836. doi:10.1021/acs.jcim.2c00822
45. Qian Y, Ni W, Xianyu X, Tao L, Wang Q. DoubleSG-DTA: deep learning for drug discovery: case study on the non-small cell lung cancer with EGFR(T790M) mutation. Pharmaceutics. 2023;15(2):675. doi:10.3390/pharmaceutics15020675
46. Zhu Z, Yao Z, Zheng X, et al. Drug–target affinity prediction method based on multi-scale information interaction and graph optimization. Comput Biol Med. 2023;167:107621. doi:10.1016/j.compbiomed.2023.107621
47. Yan X, Gu C, Feng Y, Han J. Predicting drug-drug interaction with graph mutual interaction attention mechanism. Methods. 2024;223:16–25. doi:10.1016/j.ymeth.2024.01.009
48. Yu Y, Huang K, Zhang C, Glass LM, Sun J, Xiao C. SumGNN: multi-typed drug interaction prediction via efficient knowledge graph summarization. Bioinformatics. 2021;37(18):2988–2995. doi:10.1093/bioinformatics/btab207
49. Chen X, Liu X, Wu J. GCN-BMP: investigating graph representation learning for DDI prediction task. Methods. 2020;179:47–54. doi:10.1016/j.ymeth.2020.05.014
50. Liu Z, Lin S, Zhou J, et al. Machine-learning model for the prediction of acute orthostatic hypotension after levodopa administration. CNS Neurosci Ther. 2024;30(3):e14575. doi:10.1111/cns.14575
51. Fuadah YN, Qauli AI, Marcellinus A, Pramudito MA, Lim KM. Machine learning approach to evaluate TdP risk of drugs using cardiac electrophysiological model including inter-individual variability. Front Physiol. 2023;14:1266084. doi:10.3389/fphys.2023.1266084
52. Pikalyova K, Orlov A, Horvath D, Marcou G, Varnek A. Predicting S. aureus antimicrobial resistance with interpretable genomic space maps. Mol Informatics. 2024;43(5):e202300263. doi:10.1002/minf.202300263
53. Lee S, Yoo S. InterDILI: interpretable prediction of drug-induced liver injury through permutation feature importance and attention mechanism. J Cheminf. 2024;16(1):1. doi:10.1186/s13321-023-00796-8
54. Krix S, DeLong LN, Madan S, et al. MultiGML: multimodal graph machine learning for prediction of adverse drug events. Heliyon. 2023;9(9):e19441. doi:10.1016/j.heliyon.2023.e19441
55. Liu TX, Zheng JX, Chen Z, Zhang ZC, Li D, Shi LP. An interpretable machine-learning model for predicting the efficacy of nonsteroidal anti-inflammatory drugs for closing hemodynamically significant patent ductus arteriosus in preterm infants. Front Pediatrics. 2023;11:1097950. doi:10.3389/fped.2023.1097950
56. Yu J, Wang J, Zhao H, et al. Organic compound synthetic accessibility prediction based on the graph attention mechanism. J Chem Inf Model. 2022;62(12):2973–2986. doi:10.1021/acs.jcim.2c00038
57. Yao L, Guan J, Xie P, et al. AMPActiPred: a three-stage framework for predicting antibacterial peptides and activity levels with deep forest. Protein Sci. 2024;33(6):e5006. doi:10.1002/pro.5006
58. Fang Y, Xu F, Wei L, et al. AFP-MFL: accurate identification of antifungal peptides using multi-view feature learning. Briefings Bioinf. 2023;24(1):1–12. doi:10.1093/bib/bbac606
59. Zhang S, Zhao Y, Liang Y. AACFlow: an end-to-end model based on attention augmented convolutional neural network and flow-attention mechanism for identification of anticancer peptides. Bioinformatics. 2024;40(3).
60. Karim T, Shaon MSH, Sultan MF, Hasan MZ, Kafy AA. ANNprob-ACPs: a novel anticancer peptide identifier based on probabilistic feature fusion approach. Comput Biol Med. 2024;169:107915. doi:10.1016/j.compbiomed.2023.107915
61. Deng H, Ding M, Wang Y, Li W, Liu G, Tang Y. ACP-MLC: a two-level prediction engine for identification of anticancer peptides and multi-label classification of their functional types. Comput Biol Med. 2023;158:106844. doi:10.1016/j.compbiomed.2023.106844
62. Guan J, Yao L, Chung CR, Chiang YC, Lee TY. StackTHPred: identifying tumor-homing peptides through GBDT-based feature selection with stacking ensemble architecture. Int J Mol Sci. 2023;24(12):10348. doi:10.3390/ijms241210348
63. Yao L, Li W, Zhang Y, et al. Accelerating the discovery of anticancer peptides through deep forest architecture with deep graphical representation. Int J Mol Sci. 2023;24(5):4328. doi:10.3390/ijms24054328
64. Akbar SA, Mohamed HG, Ali H, et al. Identifying neuropeptides via evolutionary and sequential based multi-perspective descriptors by incorporation with ensemble classification strategy. IEEE Access. 2023;11:49024–49034. doi:10.1109/ACCESS.2023.3274601
65. Nath A. Physicochemical and sequence determinants of antiviral peptides. Biologia futura. 2023;74(4):489–506. doi:10.1007/s42977-023-00188-x
66. Akbar S, Ali F, Hayat M, Ahmad A, Khan S, Gul S. Prediction of Antiviral peptides using transform evolutionary & SHAP analysis based descriptors by incorporation with ensemble learning strategy. Chemometrics Intell Lab Syst. 2022;230:104682. doi:10.1016/j.chemolab.2022.104682
67. Charoenkwan P, Chumnanpuen P, Schaduangrat N, Oh C, Manavalan B, Shoombuatong W. PSRQSP: an effective approach for the interpretable prediction of quorum sensing peptide using propensity score representation learning. Comput Biol Med. 2023;158:106784. doi:10.1016/j.compbiomed.2023.106784
68. Charoenkwan P, Chumnanpuen P, Schaduangrat N, Lio P, Moni MA, Shoombuatong W. Improved prediction and characterization of blood-brain barrier penetrating peptides using estimated propensity scores of dipeptides. J Computer-Aided Mol Design. 2022;36(11):781–796. doi:10.1007/s10822-022-00476-z
69. Charoenkwan P, Yana J, Schaduangrat N, Nantasenamat C, Hasan MM, Shoombuatong W. iBitter-SCM: identification and characterization of bitter peptides using a scoring card method with propensity scores of dipeptides. Genomics. 2020;112(4):2813–2822. doi:10.1016/j.ygeno.2020.03.019
70. Makowski EK, Chen HT, Wang T, et al. Reduction of monoclonal antibody viscosity using interpretable machine learning. mAbs. 2024;16(1):2303781. doi:10.1080/19420862.2024.2303781
71. Makowski EK, Wang T, Zupancic JM, et al. Optimization of therapeutic antibodies for reduced self-association and non-specific binding via interpretable machine learning. Nat Biomed Eng. 2024;8(1):45–56. doi:10.1038/s41551-023-01074-6
72. Lee S, Kim J, Park SW, Jin SM, Park SM. Toward a fully automated artificial pancreas system using a bioinspired reinforcement learning design: in silico validation. IEEE J Biomed Health Inform. 2021;25(2):536–546. doi:10.1109/JBHI.2020.3002022
73. Ung CY, Li H, Cao ZW, Li YX, Chen YZ. Are herb-pairs of traditional Chinese medicine distinguishable from others? Pattern analysis and artificial intelligence classification study of traditionally defined herbal properties. J Ethnopharmacol. 2007;111(2):371–377. doi:10.1016/j.jep.2006.11.037
74. Yao L, Zhang Y, Wei B, et al. Discovering treatment pattern in traditional Chinese medicine clinical cases by exploiting supervised topic model and domain knowledge. J Biomed Informat. 2015;58:260–267. doi:10.1016/j.jbi.2015.10.012
75. Tian S, Wang J, Li Y, Xu X, Hou T. Drug-likeness analysis of traditional Chinese medicines: prediction of drug-likeness using machine learning approaches. Mol Pharmaceut. 2012;9(10):2875–2886. doi:10.1021/mp300198d
76. Shin HK, Huang R, Chen M. In silico modeling-based new alternative methods to predict drug and herb-induced liver injury: a review. Food Chem Toxicol. 2023;179:113948. doi:10.1016/j.fct.2023.113948
77. Ma J, Yu Z, Chen T, et al. The effect of Shengmai injection in patients with coronary heart disease in real world and its personalized medicine research using machine learning techniques. Front Pharmacol. 2023;14:1208621. doi:10.3389/fphar.2023.1208621
78. Yang M, Chen JL, Xu LW, Ji G. Navigating traditional Chinese medicine network pharmacology and computational tools. Evidence-Based Complementary Alternative Med. 2013;2013:731969. doi:10.1155/2013/731969
79. Drakakis G, Moledina S, Chomenidis C, Doganis P, Sarimveis H. Decision trees for continuous data and conditional mutual information as a criterion for splitting instances. Comb Chem High Throughput Screening. 2016;19(5):423–428. doi:10.2174/1386207319666160414105217
80. Zhang T, Liu Z, Ma Q, et al. Identification of dendrobium using laser-induced breakdown spectroscopy in combination with a multivariate algorithm model. Foods. 2024;13(11):1676. doi:10.3390/foods13111676
 © 2025 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms.php
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2025 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms.php
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.